The thing that surprised me most, following the publication of that paper, is how most people don't actually know what bubble sort is. Or rather, the key question actually is: what is NOT bubble sort? In other words, what makes some pseudocode count as (variants of) bubble sort and others not? Obviously you can make variations such as going through the for loops either up or down, exiting or not exiting the loops early, etc. But what is the defining characteristic of bubble sort?
I have always thought that was obvious, but based on people's reactions on twitter, it seems many people got that totally wrong. It appears that more than half of people believe the following (or perhaps anything of that general shape, such as the one described in my paper, but never mind that) is bubble sort:
for i = 1 to n
for j = i+1 to n
if A[i] > A[j] then
swap A[i] and A[j]
So much so, that after my paper appeared, someone immediately went to wikipedia to change the entry on bubble sort to this "simplest" and "most instructive" form:
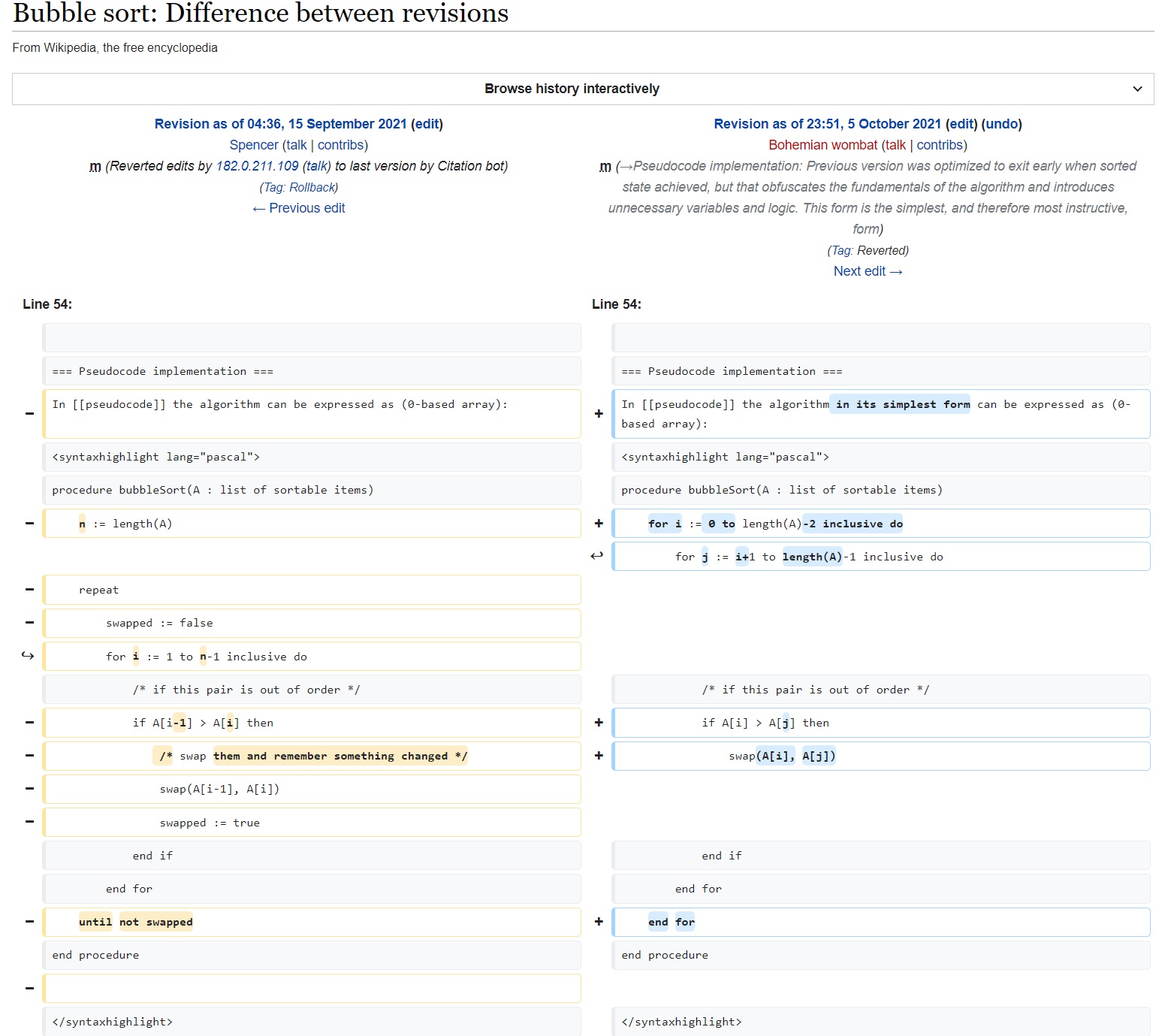
Thankfully it was reverted the next day:

No. Bubble sort only compares adjacent elements. That is, it compares and swaps A[j-1] with A[j]. Knuth said that in TAOCP, Wikipedia says that, every coding tutorial that appears when you google "bubble sort" says that. Yet for some reason a very large number of people genuinely believe that the other algorithm (shown at the top of the page, and the wikipedia edit) is bubble sort.
That algorithm is called "exchange sort" in my paper and in a number of places, including Wikipedia. It has some other names like "jump-down sort" or "3-line selection sort".
At one point my algorithm was mentioned as a "variation" in the wikipedia article for bubble sort, but someone removed it because it "doesn't even look like bubble sort":
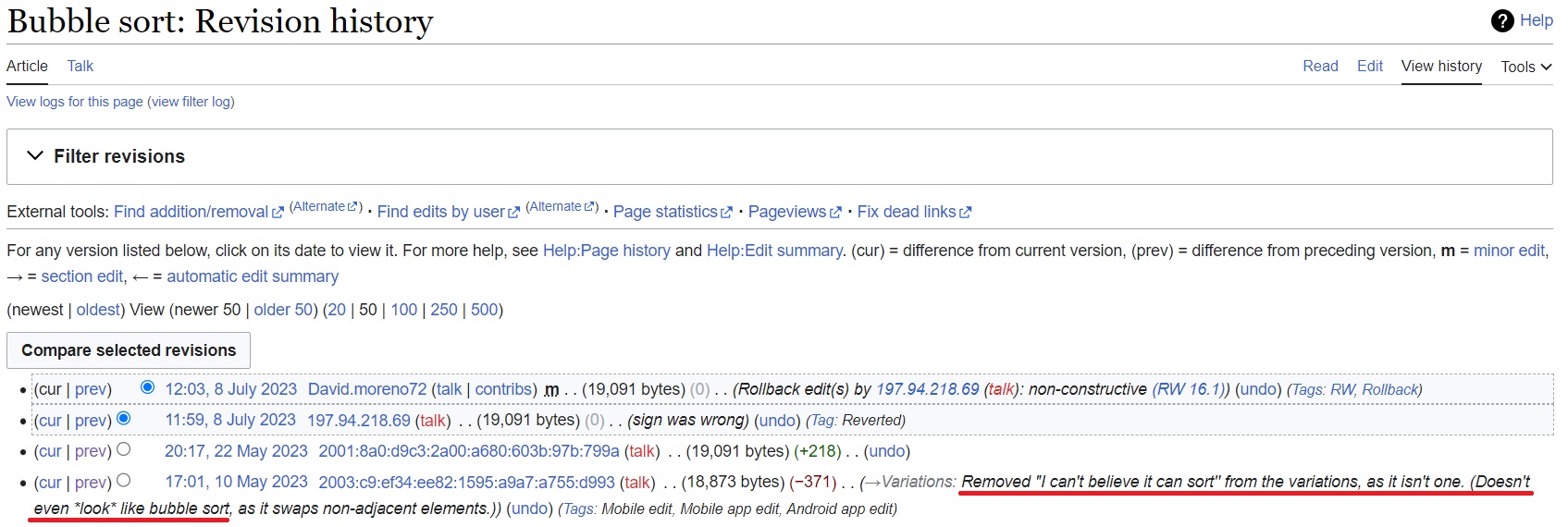
I absolutely agree. If only more people think the same...
Even worse, some people may believe that anything of that general shape (two nested loops and a swap) counts as bubble sort. So that includes exchange sort and the one in my paper. I've even seen someone passionately arguing that the defining characteristic of bubble sort is that it compares every pair of elements, seemingly quoting TAOCP to argue that the exchange sort pseudocode is bubble sort, even though the paragraph he is quoting specifically said that an algorithm that compares every pair is NOT bubble sort!
Wikipedia says exchange sort is often confused with bubble sort. I think we have proof of that statement now.
Perhaps some people have the following code in mind instead when they said my algorithm is just "unoptimized bubble sort":
for i = 1 to n-1
for j = 1 to n-1
if A[j] > A[j+1] then
swap A[j] and A[j+1]
This is indeed a correct, unoptimized, bubble sort. Because, you see, it again only compares adjacent elements! (The variable i does not appear inside the body.) So it is bubble sort, but not my sort, despite how similar-looking they are. (The guy who changed the wikipedia entry above: you might want to try this one instead...)
Well, you want to challenge Knuth?
OK, he didn't actually say that adjacent elements is the "defining" characteristic. But I think it is uncontroversial that, if you want to classify some algorithms, that should be based on the principles they are based on, what their behaviours are, rather than their "appearances" such as "it has two nested for loops".
For example, earlier we said exchange sort is also called "3-line selection sort". The reason is that it indeed works like selection sort: in each iteration of the outer loop, it picks the smallest element in A[i..n] and put it in A[i]. Even though the code does not look like the typical selection sort, and it is slower and makes more unnecessary moves, the principle is the same.
In the case of bubble sort, the situation is a bit more ambiguous because it can be coded in a way that it satisfies the selection sort invariant, so you might argue that their "principle" or "behaviour" are the same. But bubble sort has a different intuition. It's in the name, guys. You can only bubble things up one step at a time, and this is done by swapping adjacent elements. Have you seen a bubble jump directly from the bottom of a beer glass to the top?
Meanwhile, if you have (correctly) run my algorithm, you will see it moves elements totally differently from any of these sorts (for example, it destroys an already sorted input before putting it back together), even though the appearance of the code is very similar to exchange sort or unoptimized bubble sort. It is in fact an example of how code with similar appearances do not have similar behaviours, and so a justification of why one should not classify algorithms based on how they "look like".
So in summary, the algorithm in my paper, and exchange sort, and bubble sort, are three different things, and one is not some "unoptimized version" of another, okay?
At first, I didn't know why people have this collective misunderstanding. I genuinely wasn't expecting that. Bubble sort has always been "swap adjacent elements" in my head since I learnt it at school decades ago (it was my first sorting algorithm, in fact the first algorithm of any kind I learnt), and it never crossed my mind that other people would think that bubble sort is something else. Had I known so many people got it wrong, I would have written the paper in a slightly different way.
Maybe they purged bubble sort from the curriculum so successfully, no one knows what it is anymore, just a vague sense that it is "simple but n^2 time" - and therefore two for loops?
Or is this another example of the Mandela effect? Maybe in a parallel universe, that one is called bubble sort, and that other universe "crossed" with ours somehow.
OK, less sci-fi and more seriously: as I was writing this page (the necessity of which is quite sad actually), I came to realise the answer, which was already touched upon in the previous section. There is something fundamentally wrong how algorithms are learnt (and taught). Algorithms should be learnt by understanding how it works, the intuition and principle behind it. It would appear, however, that most people "learn" algorithms not by understanding anything, but by just remembering the code. Since it "looks like" bubble sort, it must be bubble sort then, they conclude. Which sadly shows how bad the state of our education system is.
It probably also explains why some people find my algorithm uninteresting even after knowing that it moves elements around differently. Because they never care about the intuition and principle behind the algorithms. Your algorithm destroys an already sorted list? The inequality sign is in the opposite direction? So what, they ask, seemingly not realising those defy the intuition of most sorting algorithms. The "shape of the pseudocode" is all that matters to them.