cms |
|||
ABOUT |
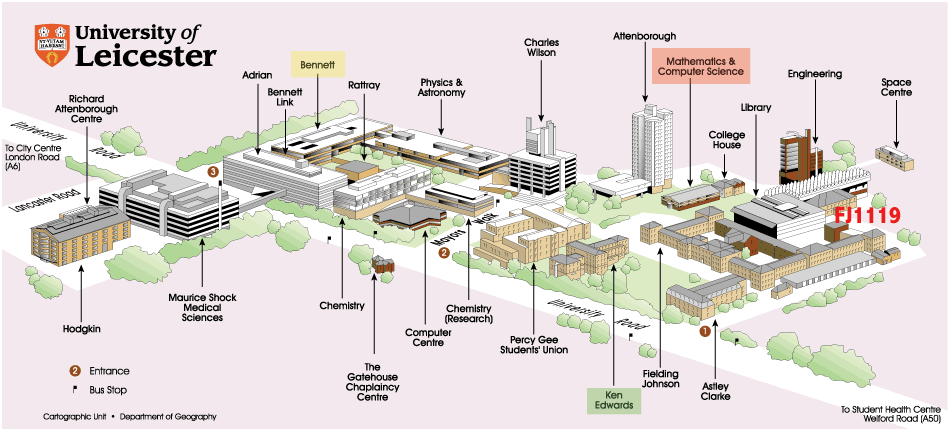
Computer Science Seminars and Short Courses — 2006/07A map of the campus is here (most of us are in the Mathematics and Computer Science building). Further maps and directions are available from this page.
Semester 2Seminar programme
Seminar detailsModel-oriented Formal Methods: experience in semantics, tools and industry application.
John Fitzgerald (Centre for Software Reliability Newcastle University)
The term "lightweight formal methods" gained currency just over ten
years ago following the publication of several articles calling on the
formal methods community to develop methods and tools that provide at
least some of the benefits of formalism, without requiring the
wholesale application of highly specialised technology. The community
working around the Vienna Development Method (VDM) rose to this
challenge. In this talk, we draw on experience in developing the
semantics and tool support for VDM, and in applying VDM technology in
industry, to identify achievements and challenges in providing
lightweight but effective formal methods.
This talk is based on a forthcoming paper written with Peter Gorm
Larsen of the Engineering College, Aarhus, Denmark.
Subject-Oriented Modeling and the Identification of Risk in Enterprise
Bernie Cohen (City University London, Boxer Research Ltd)
The classical engineering modeling frameworks are appropriate for the modeling of 'objects', but not for subjects who, being embodied individuals, anticipate the satisfaction of their own demands.
We model the object with a view to reifying the model as a system, but the only reification of the subject's model is the subject herself.
The modeler of an object asumes that the construction of the model does not change the object, but the modeler of the subject must be aware that the act of modeling is an intervention in the subject's being.
Similarly, the classical business modeling frameworks are appropriate for the modeling of enterprises that adopt 'positional' strategies, but not for those that adopt 'relational'strategies who, as subjects, take 'power to the edge', anticipating the satisfaction both of their own demands and of their clients'.
We model the positional enterprise with a view to reifying the business model in an information system but, as systems analysts have reported for years, the act of modeling often alters the client's business model.
We model the relational enterprise with a view to identifying, and thereby mitigating, the risks to which the enterprise is exposed by the variety of demand that its clients present and by their need for 'through life capability management'.
We present PAN, a modeling framework that is appropriate for eliciting and analysing the models of subjects and of relational enterprises.
We invite interest in pursuing research into the structure of PAN's meta-models and the philosophical, psychological and mathematical issues that they raise.
Computing with real real numbers, or, what is sin(10^40)?
Achim Jung (University of Birmingham)
A lot of our work as computer scientists is concerned with
modelling the real world inside a computer system. The more accurate such
a model is the more useful and reliable will the program be, but the
limitations of computers force us to make compromises all the time between
accuracy and effciency.
Computing with numbers (integers and reals) is a case in point; although
the manipulation of numbers was the very reason why computers were
invented in the first place (in the late 30s and early 40s), the problem
of number representation is still not solved in today's main-stream
languages.
In this talk I will explain what the issues are, starting briefly with
the representation of integers, and then move on to the real
numbers. A large part of the talk will be devoted to the shortcomings
of floating point representation, and if there is time I will explain
how one can represent and manipulate real numbers without loss of
accuracy.
If you would like to get into the right mood for this lecture then use
your pocket calculator, computer, or the internet to find out what the
value of sin(10^40) is.
Descriptive and Computational Complexity
Anuj Dawar (University of Cambridge)
In this talk I will introduce the study of descriptive complexity and
compare it to the more classical notion of computational complexity.
This will be motivated by the study of languages for generic queries
in relational databases. I will review Fagin's well-known theorem
giving a descriptive characterisation of NP - the class of problems
decidable nondeterministically in polynomial time. I will also
describe current progress on the long standing open problem of
obtaining a descriptive characterisation of P.
Slides of
the talk, background information: E. Grädel,
Finite model theory and descriptive complexity, in Finite Model Theory
and Its Applications, Springer-Verlag, 2007, and the recent paper
which contains the result mentioned near the end of the talk: A. Atserias,
A. Bulatov and A. Dawar Affine Systems of Equations and Counting
Infinitary Logic, preprint NI07002-LAA, Isaac Newton Institute of
Mathematical Sciences (2007).
Dynamics in Knowledge, Belief and Preference
Dick de Jongh (Amsterdam)
A new approach to preference in logic is developed. There is a basis
of properties (issues, priorities, constraints) from which preference
over objects is constructed. First, this preference relation is
constructed directly (objective preference, betterness), afterwards
belief is interposed in the construction (real, subjective
preference). The latter opens the possibility of interpreting
preference logic in epistemic-doxastic logic, the logic of knowledge
and belief (of agents). The dynamic form of this logic, DEL (dynamic
epistemic logic), developed by Gerbrandy, van Benthem, Baltag and
others, can account for changes brought about by new information
available to the agents. For belief statements this was done by
introducing conditional belief, belief under certain assumptions. In
our approach conditional preference takes its place naturally, and in
this manner preference logic can take advantage of the attainments of
DEL. The talk will require little or no prior knowledge. It is based
on work with Fenrong Liu, Optimality,
Belief and Preference, ILLC 2006.
Slides in pdf and ps
Complete Sequent Calculi for Induction and Infinite Descent
James Brotherston (Imperial College)
I will give an overview of a paper recently submitted by myself and
Alex Simpson, which is based upon (some of) my PhD work under his
supervision at LFCS in Edinburgh.
We give completeness and cut-eliminability results for two different
styles of reasoning with inductively defined predicates, each style
being encapsulated by a corresponding sequent calculus proof system.
The first system supports traditional proof by induction, with
induction rules formulated as sequent rules for introducing
inductively defined predicates on the left of sequents. We show
this system to be cut-free complete with respect to a natural class
of Henkin models; the eliminability of cut follows as a corollary.
The second system uses infinite (non-well-founded) proofs to
represent arguments by infinite descent. In this system, the left
rules for inductively defined predicates are simple case-split
rules, and an infinitary, global condition is imposed on proof trees
to ensure soundness. We show this system to be cut-free complete
with respect to standard models, and again infer the eliminability
of cut.
The second infinitary system is unsuitable for formal reasoning.
However, it has a natural restriction to proofs given by regular
trees, i.e., to those proofs representable by finite graphs. This
restricted "cyclic" system subsumes the first system for proof by
induction. We conjecture that the two systems are in fact
equivalent, i.e., that proof by induction is equivalent to regular
proof by infinite descent.
Abstract Syntax: Substitution and Binders
John Power (Edinburgh)
We summarise Fiore et al's paper on variable substitution and binding,
then axiomatise it. Generalising their use of the category $\FF$ of
finite sets to model untyped cartesian contexts, we let $S$ be an
arbitrary pseudo-monad on $\Cat$ and consider $(S1)^{op}$: this
generality includes linear contexts, affine contexts, and contexts for
the Logic of Bunched Implications. Given a pseudo-distributive law of
$S$ over the (partial) pseudo-monad $\mathit{T_{coc}}- =
[(-)^{op},Set]$ for free cocompletions, one can define a canonical
substitution monoidal structure on the category $[(S1)^{op},Set]$,
generalising Fiore et al's substitution monoidal structure for
cartesian contexts: this provides a natural substitution structure for
the above examples. We give a concrete description of this
substitution monoidal structure in full generality. We can then give an
axiomatic definition of a binding signature, then state and prove an
initial algebra semantics theorem for binding signatures in full
generality, once again extending the definitions and theorem of Fiore
et al. A delicate extension of the research includes the category
$Pb(Inj^{op},\Set)$ studied by Gabbay and Pitts in their quite
different analysis of binders, which we compare and contrast with that
of Fiore et al.
Rank/select operations on large alphabets: a tool for text indexing
Srinivasa Rao (IT University Copenhagen)
Joint work with Alexander Golynski (University of Waterloo, Waterloo,
ON, Canada) and J. Ian Munro (University of Waterloo, Waterloo, ON,
Canada)
We consider a generalization of the problem of supporting
rank and select queries on binary strings. Given a string
of length n from an alphabet of size \sigma, we give the
first representation that supports rank and access
operations in O(\lg \lg \sigma) time, and select in O(1)
time while using the optimal n \lg \sigma + o(n \lg
\sigma) bits. The best known previous structure for this
problem required O(\lg \sigma) time, for general values of
\sigma. Our results immediately improve the search times
of a variety of text indexing methods.
Neil Ghani (University of Nottingham)
Abstract: Traditional data types such as the natural numbers can be
described as inductive types. Lists are slightly more complicated in
that for each type X, we have the type List X - we may say that lists
thus form a family of inductve types indexed by types.
The last ten years have seen increasing interest in more sophisticated
examples of types which are not families of inductive types, but
rather inductive families of types. I will explain the intution behind
this word play and consider the possibilities for indexing. Indexing
by types leads to an impredicative system much like Haskell. The
alternative is to index by terms which leads to a dependent type
system as favoured by languages such as Agda and Epigram.
I will compare the two approaches and provide a shocking conclusion ...
Slides in pdf
Efficient P2P Overlay Systems using Multidestination Multicast Routing
Mario Kolberg ()
Structured P2P systems come in two flavours: multi-hop and one-hop
overlays. One-hop overlays offer significant latency reduction
compared to multi-hop overlays, but at a cost of increased maintenance
traffic and routing table size. However, many peer-to-peer overlay
operations are inherently parallel and this parallelism can be
exploited by using multi-destination multicast routing, resulting in
significant message reduction in the underlying network.
This talk examines two techniques for routing table maintenance:
active stabilisation using EDRA (Event Detection and Reporting
Algorithm) and opportunistic updating using the EpiChord
algorithm. Some errors in EDRA are identified, which lead to incorrect
event detention and propagation, and appropriate solutions
proposed.
Using simulation, message savings in the two algorithms are evaluated
when multi-destination multicast routing is used in place of unicast
messages. It is shown that the message overhead in one-hop overlays
can be significantly reduced using this approach.
Finally a variable hop approach is introduced which combines the
opportunistic and active maintenance mechanisms in a single overlay.
Action-state based Model Checking
Stefania Gnesi (ISTI-CNR, Pisa, Italy)
These talks aim to present the possibilities offered by model checking
tools for the verification of distributed, mobile, object-oriented
systems, modelled as variants of Labelled Transition Systems.
An action-state based logical framework for the analysis and verification
of complex systems will be presented and related with classical state
based logics using instead Kripke structures as semantic model. The
defined logic combines the action paradigm, classically used for
describing systems using labelled transitions systems together with the
predicates that are true over states as captured using Kripke structures.
Model checking algorithms and tools for this logical framework will be
also discussed.
Semester 1Seminar programme
Seminar details
Susan Stepney (University of York)
Biological processes are made from physical material, they
are situated in and interact with a physical environment,
and they are constrained by physical laws such as
conservation of matter and energy. Software systems, on the
other hand, are informational, exist in the virtual world of
the computer, and labour under no such constraints. How does
this difference matter? Can the advantages of embodiment be
achieved in virtual environments? What are design principles
for embodied computational systems?
Slides
Algorithms for Wireless Ad-Hoc Networks
Thomas Erlebach (University of Leicester)
In recent years there has been an increasing interest in
wireless ad-hoc networks. Contrary to wired networks and
cellular networks, there is no fixed infrastructure and
the network is formed spontaneously by the participating
nodes. Questions such as efficient topology control and
routing lead to interesting algorithmic problems. We will
give an introduction to this topic and then discuss some
algorithms for unit disk graphs, a popular simplified
model for wireless ad-hoc networks.
Hyper-computation with Newtonian machines
John Tucker (University of Wales Swansea) Pelorus - getting to where you want to be
Vic Stenning (Anshar Ltd) Pelorus is a tool for formulating and
delivering change within a business, whether at the level of
overall strategy, a single programme or a specific
project. It helps to address and 'dissolve' many of the
problems of change and, by so doing, increases the
probability of meeting objectives and delivering the desired
outcomes. Key themes include the active participation of all
stakeholders, collective responsibility, dialogue,
alignment, continuous learning, dynamic adjustment, and
convergence.
John Mc Call (Robert Gordon University, Aberdeen) Estimation of Distribution Algorithms (EDA)
are derived from Genetic Algorithms. In an EDA, a
probabilistic model is constructed from a population of
solutions. The model is then sampled repeatedly to generate
a successor population of solutions, thus replacing the
traditional use of genetic operators to breed children from
selected solutions.
EDAs apply selective pressure by "estimating the
distribution" of good solutions. A common approach is to select good
solutions from the population and then construct a joint probability
distribution of solution variables. The jpd is represented using a
Bayesian Network and an armoury of techniques now exists to build a
Bayesian Network from a population of solutions. Sampling the jpd then
generates the next population.
In this talk, I will describe how Markov Networks can be
used to estimate the jpd. The approach has benefits in
improving evolution but at some computational expense in
building the model. I will demonstrate the costs and
benefits of a Markov Network EDA by comparing with other
EDAs on a range of problems.
Stefan Dantchev (University of Durham)
I will announce the strange engagement of two areas of
Computational Complexity that have so far known very
little about each other, Propositional Proof Complexity
and Parameterised Complexity. The "big" motivation that
brought them together is a general programme for
separating FPT and W[2], inspired by and very similar to
the NP vs co-NP programme of Cook and Reckhow. I will
then prove a specific result in the newly created area of
Parameterised Proof Complexity, the so-called Complexity
Gap for Parameterised Tree-like Resolution. The gap for
(classical) Tree-like Resolution has been know for quite a
while; it is a dichotomy theorem that characterises and
separates the propositional tautologies expressible in
First-Order Logic that are easy for Tree-like Resolution
from the ones that are hard. Our theorem refines the hard
case by splitting it into two sub-cases, the easier of
which is a fixed-parameter tractable. The separating
criterion refers to the existence of a finite dominating
set in a certain infinite hyper-graph.
The query equivalence problem for XML path languages
Balder ten Cate (University of Amsterdam) XPath is a language for navigating XML
documents. It is part of the W3C standard XML querying and
processing languages XQuery and XSLT. From the perspective
of logic, XPath can be understood as a variant of modal
logic interpreted on finite trees. In this talk, I will
discuss two "logical" aspects of XPath (as well as of some
variants of the languages proposed in the literature): - Expressivity and succinctness:
Which paths through XML documents can be described in
XPath, and how succinctly? One way to answer this is by
comparing XPath to more well established and understood
languages such as first-order logic. - Static
analysis:
What is the complexity of testing whether two XPath
expressions are equivalent (always give the same answer)?
Can we find a complete set of equivalence-preserving
rewrite rules (i.e., so that every two equivalent
expressions can be rewritten to each other using these
rules)? Based on joint work with Maarten Marx, and
with Carsten Lutz.
Reasoning about Code Pointers (Separation Logic for Higher-Order Store)
Bernhard Reus (University of Sussex)
Separation Logic is a sub-structural logic that supports
local reasoning for imperative programs with dynamic
memory. It was designed to elegantly describe sharing and
aliasing properties of heap structures, thus facilitating
the verification of programs with pointers. Various
flavours of separation logic have been developed for heaps
containing records of basic data types. However,
languages like C or ML allow procedures to be stored on
the heap. Such type of heap is commonly referred to as
"higher-order store." This talk addresses the problem of
lifting Separation Logic from first-order to higher-order
store.
We will briefly introduce Separation Logic, explain what
we mean by higher-order store, define a simple imperative
language with dynamic memory and stored procedures and
present a Hoare-like program logic for it. The challenge
is then to prove the correctness of the fundamental rule
of Separation Logic (the Frame Rule) and of a rule dealing
with implicitly recursive stored procedures. Denotational
Semantics will be used to do this. Modeling higher-order
store as recursive domains enables us to use powerful (and
well established) results from Domain Theory. There is a
slight complication however: as the semantics needs to be
independent of the choice of locations we need to resort
to a Kripke-style functor model.
This is joint work with Jan Schwinghammer, Programming
Systems Lab, Saarland University.
Frequency Allocation in Wireless Communication Networks
Joseph Chan (King's College London)
A mobile phone network usually has geographical coverage
area divided into cells. Phone calls are serviced by
assigning frequencies to them. In order to avoid
interference, a typical way is to assign different
frequencies to two calls emanating from the same or
neighbouring cells. The frequency allocation problem is
thus to minimize the span of frequencies used to serve all
calls, without creating interference. In this talk we
study both the offline and online versions of the problem.
We also consider the variations such as different coverage
models for the networks and a more general interference
constraint.
Distributive lattice-structured ontologies
Mai Gehrke (New Mexico State University, University of Oxford) This is joint work with Fischer Nilsson and
Bruun of the Technical University of Denmark. We describe
an implementation of a language that accommodates both
ontologies and relational databases. The structures
arrived at are finite distributive lattices with
attribution operations that preserve all joins and binary
meets. The preservation of binary meets allows these
functions to model the natural join operation in
databases. A crucial feature we believe to be new is the
concept of terminal solution identifying a minimal
faithful ontology generated by the inhabited points of a
data set. The main tools we use are Kripke
frames/Birkhoff duality and adjoint operations. The work
generalises work by Frank Oles of IBM.
Refactoring Information Systems
Michael Löwe (Hannover, Germany)
We present a formal framework for the refactoring of
information systems, including the data model and the data
itself. The framework is described using category theory
and can handle addition, renaming and removal of model
objects as well as folding and unfolding within complete
and partial object compositions. A medium-sized example
(introduction of a role pattern into a customer database)
demonstrates the applicability of the approach.
demonstrates the applicability of the approach.
|
|
Author: Alexander Kurz (kurz mcs le ac uk), T: 0116 252 5356. |
|
{kind=link}